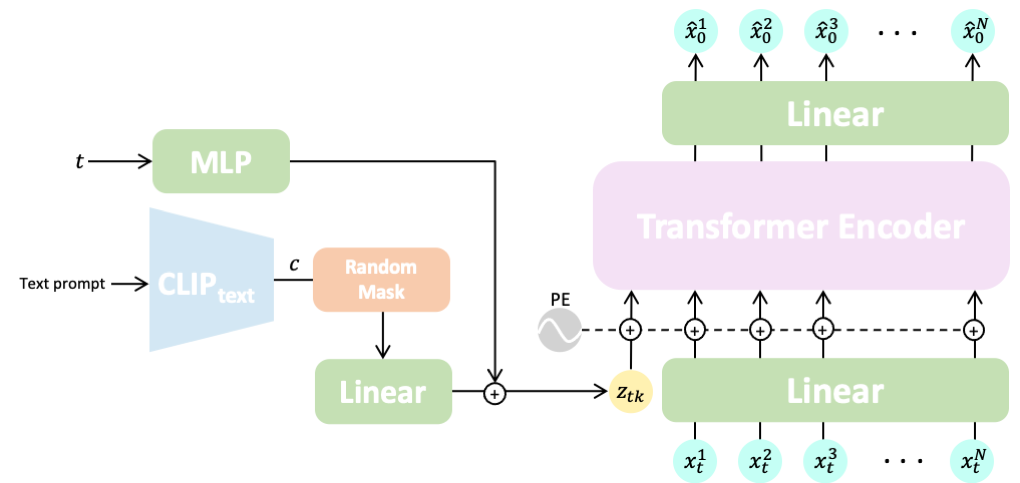
Natural and expressive human motion generation is the holy grail of computer animation. It is a challenging task, due to the diversity of possible motion, human perceptual sensitivity to it, and the difficulty of accurately describing it. Therefore, current generative solutions are either low-quality or limited in expressiveness. Diffusion models, which have already shown remarkable generative capabilities in other domains, are promising candidates for human motion due to their many-to-many nature, but they tend to be resource hungry and hard to control. In this paper, we introduce Motion Diffusion Model (MDM), a carefully adapted classifier-free diffusion-based generative model for the human motion domain. MDM is transformer-based, combining insights from motion generation literature. A notable design-choice is the prediction of the sample, rather than the noise, in each diffusion step. This facilitates the use of established geometric losses on the locations and velocities of the motion, such as the foot contact loss. As we demonstrate, MDM is a generic approach, enabling different modes of conditioning, and different generation tasks. We show that our model is trained with lightweight resources and yet achieves state-of-the-art results on leading benchmarks for text-to-motion and action-to-motion.
The MDM framework has a generic design enabling different forms of conditioning. We showcase three tasks: text-to-motion, action-to-motion, and unconditioned generation. We train the model in a classifier-free manner, which enables trading-off diversity to fidelity, and sampling both conditionally and unconditionally from the same model. In the text-to-motion task, our model generates coherent motions that achieve state-of-the-art results on the HumanML3D and KIT benchmarks. Moreover, our user study shows that human evaluators prefer our generated motions over real motions 42% of the time. In action-to-motion, MDM outperforms the state-of-the-art, even though they were specifically designed for this task, on the common HumanAct12 and UESTC benchmarks.
“A person walks forward, bends down to pick something up off the ground.”
“a person turns to his right and paces back and forth.”
“A person punches in a manner consistent with martial arts.”
Text-to-motion is the task of generating motion given an input text prompt. The output motion is expected to be both implementing the textual description, and a valid sample from the data distribution (i.e. adhering to general human abilities and the rules of physics). In addition, for each text prompt, we also expect a distribution of motions matching it, rather than just a single result.
“A person kicks.”
“A person kicks.”
“A person kicks.”
“A person kicks.”
“A person kicks.”
“A person kicks.”
“A person kicks.”
“A person kicks.”
“A person kicks.”
“A person is skipping rope.”
“A person is skipping rope.”
“A person is skipping rope.”
“A person is skipping rope.”
“A person is skipping rope.”
“A person is skipping rope.”
“A person is skipping rope.”
“A person is skipping rope.”
Action-to-motion is the task of generating motion given an input action class, represented by a scalar. The output motion should faithfully animate the input action, and at the same time be natural and reflect the distribution of the dataset on which the model is trained.
(Class) Run
(Class) Warm up
(Class) Sit
(Class) Jump
We also demonstrate completion and editing. By adapting diffusion image-inpainting, we set a motion prefix and suffix, and use our model to fill in the gap. Doing so under a textual condition guides MDM to fill the gap with a specific motion that still maintains the semantics of the original input. By performing inpainting in the joints space rather than temporally, we also demonstrate the semantic editing of specific body parts, without changing the others.
(Blue=Input, Gold=Synthesis)
(Blue=Input, Gold=Synthesis)
@inproceedings{
tevet2023human,
title={Human Motion Diffusion Model},
author={Guy Tevet and Sigal Raab and Brian Gordon and Yoni Shafir and Daniel Cohen-or and Amit Haim Bermano},
booktitle={The Eleventh International Conference on Learning Representations },
year={2023},
url={https://openreview.net/forum?id=SJ1kSyO2jwu}
}